In my last post, I briefly introduced OPIC (Object Persistance in C), which is a general serialization framework that can serialize any object without knowing its internal layout. In this post, I’ll give a deeper dive on how it works.
Still with the same disclaimer. I now work at google, and this project (OPIC including the hash table implementation) is approved by google Invention Assignment Review Committee as my personal project. The work is done only in my spare time on my own machine, and does not use and/or reference any of the google internal resources.
Rationale: key-value store performance
Key-value data retrieval is probably the most commonly used abstraction in computer engineering. It has many forms: NoSQL key value store, embedded key value store, and in-memory data structures. In terms of algorithm complexity, they are all having O(1) amortized insertion, deletion, and query time complecity. However, the actual performance ranges from 2K QPS (query per second) up to 200M QPS.
To make it easier to reason about, here I only compare read only performance. Furthermore, it’s single node, single core. In this setup, the data store should not have transaction or WAL (write ahead log) overhead; if table locking was required, only the reader lock is needed; if the data was stored on disk, the read only load should trigger the data store to cache it in memory, and the overall amortized performance theoratically should be close to what in-memory data structure can achieve.
The first tier of data stores we look at, are the full featured SQL/NoSQL database which support replication over cluster of nodes. A report created by engineers at University of Toronto is a good start: Solving Big Data Challenges for Enterprise Application Performance Management. In this report they compared Cassandra, Voldemort, Redis, HBase, VoltDB, and MySQL. Unfortunately, their report doesn’t have 100% read only performance comparison, only 95% read is reported.
- Cassandra: 25K QPS
- Voldemort: 12K QPS
- Redis: 50K QPS
- HBase: 2.5K QPS
- VoltDB: 40K QPS
- MySQL: 25K QPS
Some report gives even worse performance numbers. In this nosql benchmark, 100% read, Cassandra, HBase, and mongo are all having throughput lower than 2K QPS.
The performance of the databases above may be biased by network, database driver overhead, or other internal complexities. We now look at the second tier, embedded databases: LMDB, LevelDB, RocksDB, HyperLevelDB, KyotoCabinet, MDBM and BerkelyDB all falls into this category. The comparison of first four databases can be found in this influxdb report.
- 100M values (integer key)
- LevelDB: 578K QPS
- RocksDB: 609K QPS
- HyperLevelDB: 120K QPS
- LMDB: 308K QPS
- 50M values (integer key)
- LevelDB: 4.12M QPS
- RocksDB: 3.68M QPS
- HyperLevelDB: 2.08M QPS
- LMDB: 5.89M QPS
The performance report from MDBM benchmark is also interesting. They only provide the latency number though.
- MDBM: 0.45 us, ~= 2M QPS (?)
- LevelDB: 5.3 us, ~= 0.18 QPS (?)
- KyotoCabinat: 4.9 us, ~= 0.20 QPS (?)
- BerkeleyDB: 8.4 US, ~= 0.12 QPS (?)
I’m guessing the performance number can be very different when the keys are different. In this LMDB benchmark, LevelDB only achieves 0.13M QPS. We can see huge difference in the following in memory hash tables. I ran these benchmarks myself. The code is hosted at hash_bench.
- key: std::string
- std::unordered_map: 5.3M QPS
- sparse_hash_map: 4.4M QPS
- dense_hash_map: 9.0M QPS
- key: int64
- std::unordered_map: 106M QPS
- dense_hash_map: 220M QPS
This is the state of the art I have surveyed and experimented so far. Clearly, the in memory data structure out performs all the other solutions. There’s a big gap between the data store that can save to disk, versus pure in-memory solutions. Can we fill the gap, and create a data store with competitive performance to the best hash tables? This motivates me to build OPIC (object persistence in C), where developer can focus on writing fast in-memory data structures, and offload the serialization to a general framework.
Rethink serialization
I like the clear definition in wikipedia that describes serialization:
serialization is the process of translating data structures or object state into a format that can be stored (for example, in a file or memory buffer) or transmitted (for example, across a network connection link) and reconstructed later (possibly in a different computer environment).
In our case, we want to minimize this translation cost. The smaller the translation cost, the faster the system can load the data. Pushing this idea to extreme, what if the object have the same representation in memory and on disk? This concept is not new. Many modern serialization framework treats the serialized object as an actual in memory object with accessors. Protobuf and thrift are two implementation for such idea. However, neither protobuf nor thrift is capable to represent general data structures like linked list, trees, or (large) hash tables. These solutions lack of pointers; the only supported object relationship is inline object or inline list of objects.
Why is pointer hard for serialization? If you simply copy the pointer value for serialization, the address it pointed at would not be valid after you restore it from disk. Most general serialization framework would have to walk though all the related object user attempt to serialize, copy all the objects, either inline the object or create a special mapping of objects for cross references. In the current state of the art, either you drop the support of pointer and get minimized translation cost, or you pay high translation fee (walk through objects) for general data structure serialization. How can we do better?
Turns out, once you have a good way to represent the pointer value, you gain the benefits of both solution: cheap serialization cost and freedom to implement all types of data structures.
Key idea: Put a bound on pointer addresses
Pointers are hard to serialize because it can point to anywhere in the full virtual memory space. The solution is pretty straight forward, simply bound the objects into a heap space we control.
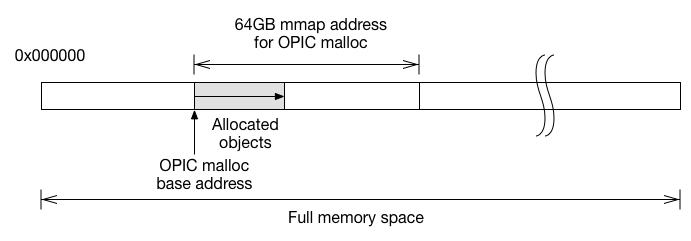
Having all objects bounded in one memory space, serialization is
simply dumping the shaded memory out, and de-serialization is mmap the
file back in memory. What if the objects contain pointers? Instead of
using pointers, we use the offset to the mmap base address to
reference objects. When accessing objects, we add the base address
back to the offset to reconstruct the pointer. Since we only use
the offset opref_t to store the pointer, even if the whole mmap
got mapped to a different address, we can still access the object
by adding a different base address to the offset. If we can ensure
all the pointers within the block are stored as opref_t, the whole
block of memory can be dumped out without any translation!
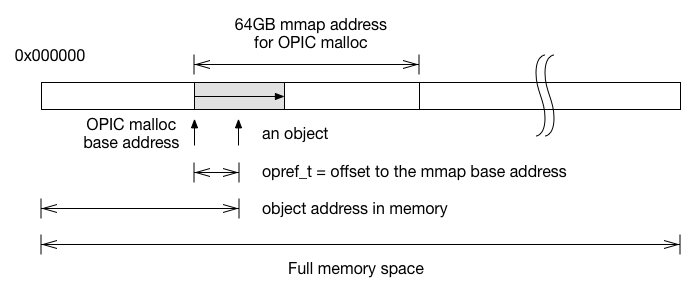
Implementation challenges
Having zero translation (serialization/de-serialization) cost is very attractive. However, building a POC took me a year (actually this is the third version, but I omitted the details). Here are the challenges I’ve found during the development.
-
All objects need to be bounded in a memory chunk. Therefore I have to write a full featured memory allocator. Writing a good one is very time consuming.
-
Programming languages with run-time pointers, like vtables, pointers in existing containers, etc. cannot be used in this framework. All containers (hash tables, balanced tress) need to be rebuilt from ground up. C++, Rust, Go all have their run-time pointers and cannot be used. The only language I can use is pure C. (This is why the project is named Object Persistence in C).
-
Serialized object cannot be transferred between architectures like 32bit/64bit, little endian or big endian. Depends on the use case, this problem might be minor.
These constraints shapes OPIC. The core OPIC API is a memory manager for allocating C objects. All the objects created by OPIC would be bounded in the 64GB mmap space. The 64GB size were chosen to hold enough objects, while user can load many OPIC mmap files in the same process.
Using OPIC malloc is very identical to standard malloc, except user need to specify an OPHeap object where the object would allocated in.
1 2 3 4 5 6 7 | |
What makes it different to regular malloc is, user can write the whole heap to disk and restoring back via file handles.
1 2 | |
To make your data structure work, you must store your pointer as
opref_t instead of regular pointer. Converting a pointer to opref_t
and vise versa is similar, except when restoring opref_t back to
pointer user must specify which OPHeap its belongs to.
1 2 3 4 5 6 | |
In regular programs, user keeps their own reference of the allocated objects. However, in the OPIC case, user would lost track of the objects they allocated after the heap is serialized. This problem can be solved by saving the pointers to the root pointer slot that OPIC provides. Each OPIC heap offers 8 root pointer slot.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 | |
This API has been through many iterations. In the early version it was a bunch of C macros for building serializable objects. Fortunately it’s simplified and became more powerful and general to build serializable applications. I believe it is now simple enough and only require a little C/C++ programming skill to master. Check out the OPIC Malloc API for details
Performance
OPIC can be used for general data serialization. The first data structure I implemented is Robin Hood hash table – a hash map variant which has good memory utilization without performance degradation. Memory utilization affects how large the serialized file is, therefore is a one of the main focus for writing OPIC containers. The details for keeping the memory footprint small is in my previous post.
The performance ends up super good: 9M QPS for in memory hash table. For non-cached performance, I tested it by de-serializing on every query. Every query would have to load the whole file back in memory via mmap, then page fault to load the query entry. For this test I got 2K QPS, which is 0.0005 second latency per load. Both cached and non-cached performance are very promising, and perhaps is very close to the upper bound for such application could perform.
Current and future scope of OPIC
Currently OPIC is implemented for building static data structures. Build the data structure once, then make it immutable. User can preprocess some data and store it with OPIC for later use. This is the minimal viable use case I can think of for the initial release, but OPIC can do more.
First of all, I want to make OPIC easier to access for more programmers. Building high level application in pure C is time consuming, therefore I’ll be writing language wrappers for C++, Python, R, and Java so that more people can benefits the high speed serialization.
Second, I’ll make OPIC able to mutate after first serialization. High level language user may treat OPIC as database of data structures that one can compose. This kind of abstraction is different to traditional database where program logic have to map to set of records. I believe this will bring in more creative usage of new types of applications.
Finally, I’d want to make OPIC to work on distributed applications. I used to work on Hadoop and big data applications. I always wonder, why people rarely talks about complexity and data structures in big data world? Why there is no framework provide data structure abstraction for big data? Isn’t the large the data size is, the more important the complexity and data structure is? Building data structure for super scale application, is the ultimate goal of OPIC.
Thank you for reading such a long post. If you also feel excited on what OPIC might achieve, please post your comment. If you want to contribute, that’s even better! The project page is at github. Feel free to fork and extend.
Edit (7/15/2017)
After posted on hacker news, some people pointed out that boost::interprocess provides similar functionality and approaches. To make a memory chunck work in different process, they also use special pointer which are offsets to base address of the mmap. The challenges are identical too. Any pointer that is unique to the process, like static members, virtual functions, references, function pointers etc. are forbidden. All the containers need to be reimplemented like I did.
To make the project succeed, I think the most important part is to provide good abstractions for users. State of the art containers, simple API to use, create extensions for other languages to use etc. Now OPIC robin hood hash container has reached (or beyond) state of the art, I’ll be continue to create more useful abstractions for people to create persistent objects.
The next container I’ll be working on is compressed trie. This would be a counter part of hash table. Hash table provides super fast random access, but there’s a high lower bound on memory usage (though I’m very close to the limit). For trie, I’ll be focus on make the memory usage as small as possible. If possible, make it succinct. Hash table can be used as short term data random look up, while trie can be used to store long term data, with compression and keeps the ability to do random look up.