In last two post I gathered the probe statistics in various scenarios. How does it impact the actual performance? I wrote some benchmarks this weekend and got useful results.
We know that hash table has O(1) amortized random read. It’s easy to tell the overall throughput in regular benchmarks. Nevertheless, it’s harder to know the performance of the worst cases: some keys has much longer probes than others. Does the performance degrade by a lot, or not so much? This is critical for applications that requires real time processing on key value look up.
In order to find the keys with potential high latency, I designed the experiments as follows:
- Insert all keys into the hash table and key buffers.
- Sort the keys in the key buffer by its probe count in the hash table.
- Test the table random read throughput from different key range in the key buffer, where the later key range should have the larger probe count.
My assumption is, the key look up performance should highly relate to the key probing count. In my first post of the learn hash table the hard way, I showed that robin hood hashing can reduce the probe count variance significantly. The plot below compares quadratic probing under 80% load and quadratic robin hood hashing under 80% load:
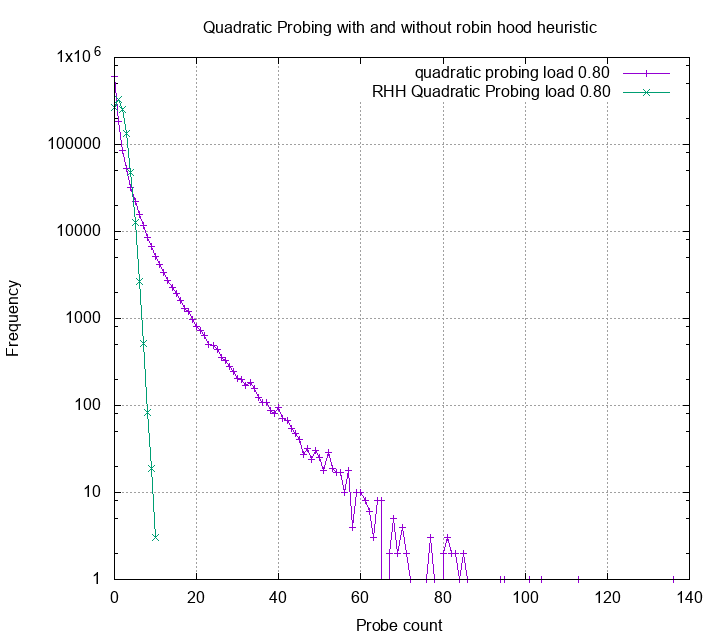
Actually, the mean of quadratic probing is slightly better than quadratic robin hood hashing (1.3 vs 1.45). However the probe count variance of quadratic probing is visibly way larger than its robin hood siblings. We’d expect the performance reflects such difference.
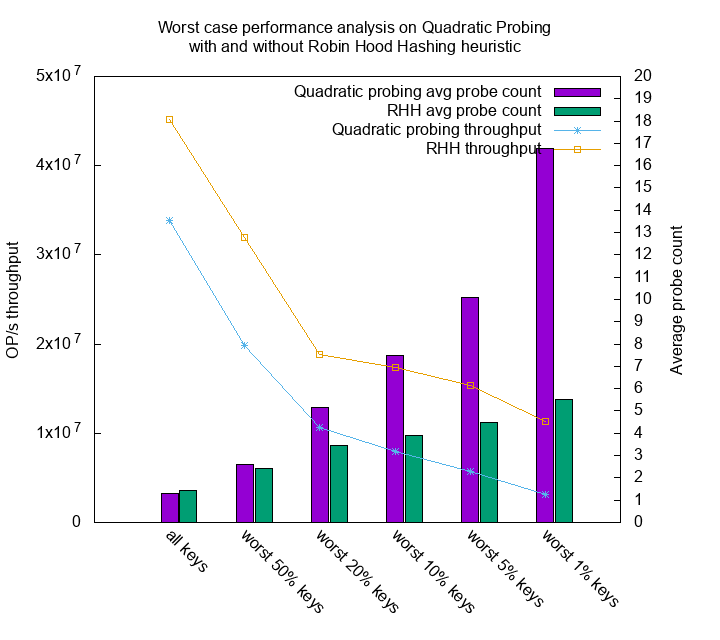
It actually does. The average read throughput of quadratic probing over all keys is 33,822,611 op/s, but for the worst 1% keys it only has throughput of 3,137,599 op/s. The difference is 10x. On the other hand, the throughput of all keys in robin hood hashing is 45,167,612 op/s, and the throughput of its worst 1% keys is 11,275,010. The difference is 4x.
There’s another interesting observation. Although quadratic probing has smaller mean of probes compare to robin hood hashing, it’s total throughput doesn’t win. My guess is having too many large probes would cause bad cache efficiency.
For instance, all probes in robin hood hashing are within 10 probes. In this experiments I use 6 bytes for key, 1 byte for key existence marker, and 8 bytes for value. 10 probes roughly converts to 100 buckets, each of size 6 + 1 + 8 = 15 bytes. Thus the worst case it need to walk through 1500 bytes, but only very few items need to go that far. On the other hand, there’s at least 100 items having probes larger than 40 probes, which takes 24000 bytes. For such a long distance you’ll have lots of CPU cache misses. This is my best guess of why robin hood hashing overtakes quadratic probing even when the average probe count is slightly larger.
I haven’t find much discussion on hash table performance corresponding to probe distribution. My hypothesis and experiments are in early stages. If you find any similar experiments, research, or report, please leave a comment! I’d like to reach out and learn more.